Contenido
- Finalidad del protocolo
- Principio general
- Dimensión epistemológica del diagnóstico
- Representación del estado del alumno
- Actualización bayesiana
- Fórmulas básicas del modelo
- Verosimilitudes generadas por el sistema
- Verosimilitudes dinámicas por pregunta
- Dificultad de las preguntas
- Número variable de niveles e hipótesis
- Tipos de preguntas admisibles
- Probabilidad de acierto por azar
- Uso de una función logística
- Selección adaptativa de la siguiente pregunta
- Reducción esperada de incertidumbre
- Mecanismos de recuperación
- Entropía de Shannon como medida de incertidumbre
- Criterios de finalización
- Resultado final
- Adaptación al contexto docente
- Reglas de diseño para la IA
- Alcance y límites
- Referencias
Ver también: Explicación matemática detallada con ejemplos numéricos →
Descargar especificación operativa para IA — archivo breve listo para adjuntar o pegar en cualquier modelo de IA
1. Finalidad del protocolo
Este documento sirve como guía para crear aplicaciones, actividades o cuestionarios educativos adaptativos basados en inferencia bayesiana y entropía de Shannon.
El objetivo no es crear un test lineal ni una secuencia rígida de preguntas, sino un sistema capaz de adaptar la experiencia del alumno a partir de sus respuestas. Cada respuesta se interpreta como una evidencia que modifica progresivamente una distribución de probabilidades sobre distintas hipótesis educativas.
Estas hipótesis pueden referirse a:
- nivel de dominio conceptual;
- errores probables;
- ideas previas;
- lagunas concretas;
- necesidades de refuerzo;
- preparación para avanzar a un nivel superior.
El sistema produce una interpretación pedagógica, no solo una puntuación.
2. Principio general
El programa usa las respuestas del alumno como evidencias para actualizar hipótesis sobre su situación de aprendizaje.
Cada respuesta modifica la estimación del sistema de forma gradual. Una sola respuesta no determina por completo el resultado.
Una respuesta correcta aumenta la plausibilidad de ciertas hipótesis y una respuesta incorrecta aumenta la plausibilidad de otras, siempre según las verosimilitudes asociadas a cada pregunta.
El sistema evita conclusiones tajantes cuando la incertidumbre sigue siendo alta.
2.1. Dimensión epistemológica del diagnóstico
El sistema no observa directamente el conocimiento del alumno. Solo observa señales evaluables —respuestas, tiempos, elecciones, ayudas usadas u otras interacciones— y las interpreta como evidencias parciales sobre distintas hipótesis educativas. Conviene precisar el alcance actual: la maquinaria de verosimilitudes de esta versión modela el acierto/fallo, el crédito parcial (\(s\)) y la opción elegida. Los tiempos de respuesta y el uso de ayudas se observan y pueden informar el resultado, pero no tienen verosimilitud definida y quedan como extensiones fuera del alcance actual —la excepción es el efecto de las pistas ofrecidas dentro de un ítem, que sí se trata en §15—.
Por eso una respuesta aislada no demuestra que una hipótesis sea cierta ni falsa. La respuesta modifica la plausibilidad de cada hipótesis según lo bien que esa evidencia encaja con ella. El diagnóstico resultante es una creencia revisada por la evidencia disponible, no una etiqueta definitiva sobre el alumno.
Esta lectura es importante desde el punto de vista pedagógico: el recurso debe hacer visible qué sabe, qué duda y con qué grado de seguridad. Cuando varias hipótesis siguen siendo plausibles, el sistema debe conservar esa incertidumbre y, si procede, elegir una nueva pregunta que ayude a distinguir entre ellas.
En este sentido, una buena pregunta no es simplemente la más difícil ni la que el alumno tiene más probabilidad de acertar, sino la que aporta mejor evidencia para decidir entre interpretaciones todavía abiertas. La selección adaptativa por ganancia esperada de información traduce esta idea a una regla operativa.
La consecuencia práctica es que el resultado final debe explicarse como una inferencia basada en evidencias: qué hipótesis queda más apoyada, qué incertidumbre permanece, qué respuestas han sido más relevantes y qué intervención pedagógica se deriva de ello.
3. Representación del estado del alumno
El estado del alumno se representa como una distribución de probabilidades sobre varias hipótesis.
Por ejemplo, en un sistema sencillo podrían usarse tres hipótesis:
- nivel básico;
- nivel medio;
- nivel avanzado.
Pero el sistema no asume obligatoriamente tres niveles. Puede adaptarse a más o menos niveles, según el contexto educativo.
También pueden usarse hipótesis no estrictamente jerárquicas, por ejemplo:
- comprende el concepto;
- confunde dos ideas próximas;
- aplica una regla de forma mecánica;
- tiene una laguna previa;
- necesita refuerzo procedimental;
- puede pasar a una tarea de ampliación.
Al inicio, si no hay información previa del alumno, el sistema puede partir de probabilidades equilibradas. Si hay información previa fiable, puede usar una distribución inicial justificada.
3.1. Estado multidimensional
El estado del alumno no tiene por qué ser una sola distribución. Cuando interesa saber no solo cuánto domina, sino qué habilidades o pasos concretos falla, el sistema puede mantener varias distribuciones de probabilidad en paralelo: una por categoría o nivel y otra por cada dimensión diagnóstica (una habilidad, un paso del proceso, un tipo de error).
Cada distribución debe actualizarse con la evidencia que le corresponde: el resultado global puede modificar la creencia sobre el nivel, y cada parte evaluada de la respuesta modifica la creencia sobre su dimensión. Si una misma respuesta global depende de varias habilidades, no conviene usar ese único acierto o fallo para actualizar todas las dimensiones independientes, porque se duplicaría la evidencia y se atribuiría mal la causa del error. Así, la estimación de nivel indica qué conviene practicar, y el diagnóstico por dimensión indica qué conviene explicar o reforzar. Cada dimensión puede tener su propia probabilidad de acierto por azar, por lo que sus porcentajes no son directamente comparables entre sí. En dimensiones ordinales, la referencia común puede ser el valor de nivel subyacente; en factores nominales de error no hay un \(\theta\) común, sino probabilidades marginales y estados como «presente», «ausente» o «indeterminado».
La decisión entre usar dimensiones independientes o perfiles completos no se traslada al docente como una decisión técnica. La toma la IA a partir de la descripción pedagógica: si cada error se manifiesta e interpreta por separado, usa factores independientes; si la respuesta esperada cambia por combinaciones de errores, si un error enmascara otro o si la intervención depende de la combinación, usa perfiles completos. Cuando \(2^k\) perfiles sea inviable, agrupa errores relacionados o diagnostica por fases.
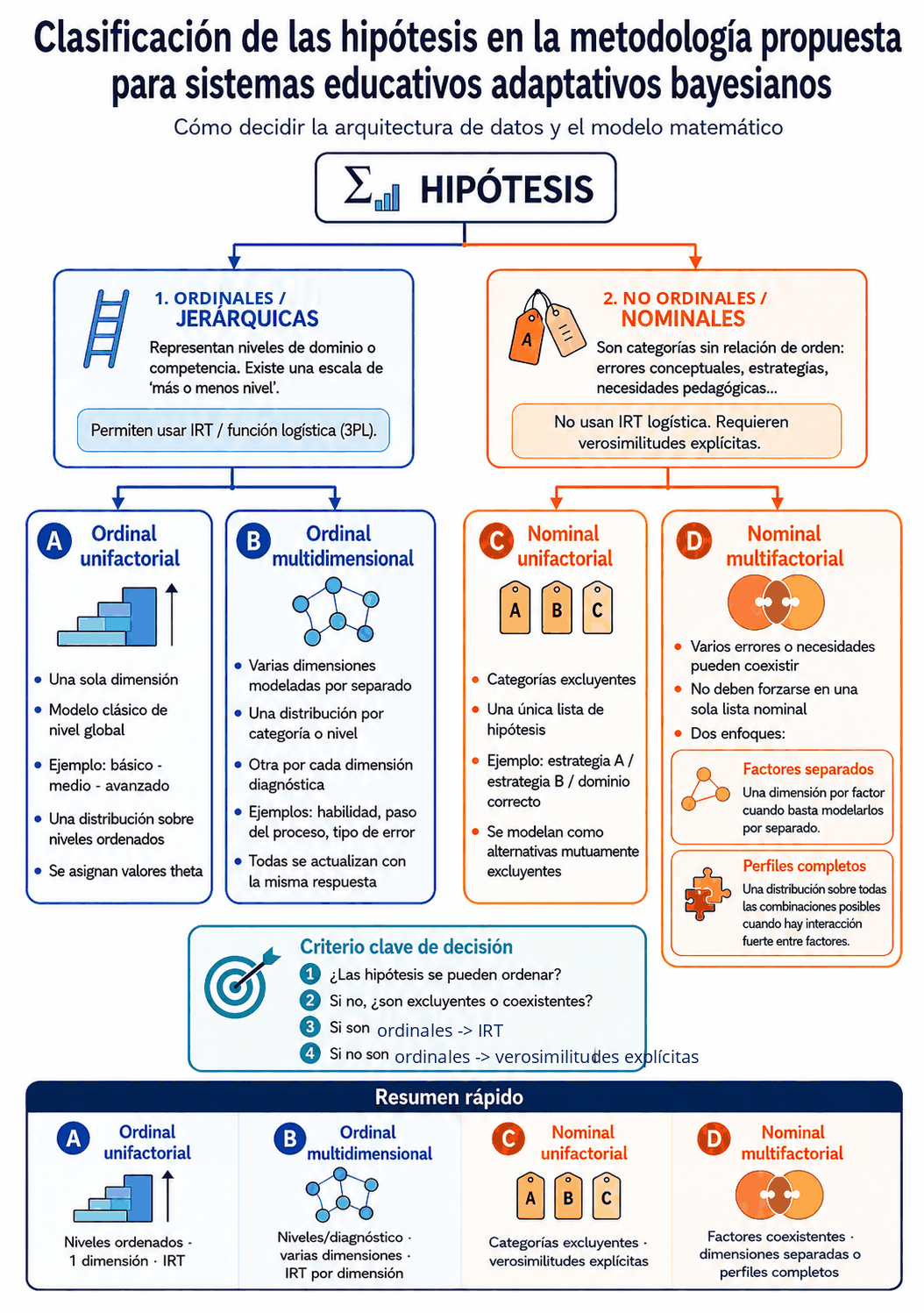
Cada tipo cuenta con un ejemplo publicado que lo ilustra:
- A · Ordinal unifactorial: test adaptativo de cultura general — un nivel global con niveles ordenados e IRT.
- A aplicado por etapas: itinerario para despejar la x — el mismo modelo ordinal dentro de un itinerario: estimación local por etapa además de la global, y promoción de etapa decidida con la evidencia generada en ella.
- B · Ordinal multidimensional: práctica de combinatoria — una distribución ordinal por tipo de problema y otra por habilidad transversal, todas actualizadas en paralelo.
- C · Nominal unifactorial: modelos mentales sobre calor y temperatura — concepciones excluyentes con verosimilitudes explícitas por opción.
- D · Nominal multifactorial: errores al comparar decimales — errores que pueden coexistir, con una probabilidad independiente por factor.
- Combinado (A + D): acentuación en ESO — nivel global y diagnóstico de errores coexistentes mediante estimaciones paralelas coordinadas.
4. Actualización bayesiana
El sistema actualiza la distribución de probabilidades mediante inferencia bayesiana.
Para cada hipótesis, se estima la probabilidad de observar la respuesta del alumno si esa hipótesis fuera cierta.
Esa probabilidad es la verosimilitud.
Si el alumno acierta una pregunta, el sistema usa la probabilidad de acierto bajo cada hipótesis. Si el alumno falla, usa la probabilidad de fallo bajo cada hipótesis.
El resultado de cada actualización es una nueva distribución de probabilidades sobre las hipótesis consideradas.
El proceso se repite tras cada respuesta.
5. Fórmulas básicas del modelo
Aunque el documento mantiene un lenguaje comprensible para docentes, incluye las fórmulas esenciales para que el sistema se implemente de forma coherente. Su desarrollo formal, las derivaciones y los ejemplos numéricos están en los Fundamentos matemáticos, que son la referencia canónica; aquí se recogen en su forma mínima.
5.1. Distribución inicial de hipótesis
Si hay \(n\) hipótesis y no existe información previa fiable, puede usarse una distribución uniforme:
Donde \(H_i\) representa una hipótesis posible sobre el estado del alumno.
El prior uniforme es adecuado para hipótesis de nivel, pero no para factores de error binarios: un uniforme sobre las combinaciones de \(k\) factores (o sobre «presente/ausente» en cada uno) equivale a afirmar que cada error tiene una probabilidad a priori del 50 % de estar presente. Eso no es neutral —es una afirmación fuerte sobre su prevalencia— y sesga las primeras preguntas hacia el falso positivo (errores que el alumno no tiene mostrados como probables). Como los errores conceptuales suelen ser minoritarios, conviene partir de un prior informativo moderado (por ejemplo, \(P(\text{error})\approx 0{,}2\)–\(0{,}3\)); el recurso lo aplica por defecto de forma automática y el docente puede ajustar la prevalencia de su grupo si lo desea, pero no está obligado.
5.2. Actualización bayesiana
Después de cada respuesta, la probabilidad de cada hipótesis se actualiza mediante:
El denominador se calcula sumando sobre todas las hipótesis:
Donde \(R\) es la respuesta observada, que puede ser acierto, fallo u otro resultado autocorregible previsto por el sistema. La derivación completa está en Fundamentos §3.
5.3. Verosimilitud de acierto y fallo
Para cada pregunta \(q\) y cada hipótesis \(H_i\), el sistema estima:
Si el alumno falla, se usa:
Estas probabilidades son las verosimilitudes que alimentan la actualización bayesiana.
5.4. Probabilidad mínima de acierto por azar
En preguntas de opción múltiple, la probabilidad mínima de acierto por azar depende del número de opciones de cada pregunta:
Donde \(c_q\) es la probabilidad de acierto por azar de la pregunta \(q\), y \(m_q\) es el número de opciones de esa pregunta.
Por ejemplo, una pregunta de cuatro opciones tiene:
Esta probabilidad pertenece a cada pregunta, no al test completo.
5.5. Generación logística de verosimilitudes
El sistema puede generar las verosimilitudes automáticamente. Una opción recomendable es usar una función logística ajustada por azar:
Donde:
- \(\theta_i\) representa numéricamente la hipótesis o nivel \(H_i\);
- \(b_q\) representa la dificultad de la pregunta \(q\);
- \(a\) controla la sensibilidad o discriminación;
- \(c_q\) es la probabilidad mínima de acierto por azar.
Esta fórmula no sustituye a Bayes. Solo genera las verosimilitudes que Bayes necesita.
El parámetro \(a\) controla la pendiente de la curva logística. Un valor alto hace que la función discrimine más entre hipótesis próximas; un valor bajo produce transiciones más suaves. Los valores habituales en psicometría oscilan entre 0.5 y 2.5. Para sistemas educativos de propósito general, valores de 1.0 a 1.5 son puntos de partida razonables; en esta metodología se fija por defecto la discriminación efectiva \(a_{\text{ef}}=1.25\) y se deriva \(a\) según el suelo de azar de cada ítem.
Ahora bien, cuánto separa la curva entre niveles no depende solo de \(a\), sino del producto \(a\,(1-c_q)\): el suelo de azar «aplana» la parte alta de la curva. Por eso conviene fijar una discriminación efectiva objetivo \(a_{\text{ef}}\) (por defecto 1.25, elegido para que la \(a\) derivada no supere 2.5 ni siquiera en verdadero/falso, donde \(c_q = 0.5\)) y calcular \(a\) en cada pregunta como \(a = a_{\text{ef}} / (1 - c_q)\). Esto no es solo para pruebas que mezclan formatos: conviene aplicarlo siempre, porque iguala la pendiente máxima de la curva y evita que el formato altere mecánicamente esa pendiente. No significa que todos los formatos aporten la misma información esperada: la selección por ganancia de información seguirá prefiriendo los ítems que discriminen mejor en el estado posterior actual. En la formulación matemática (§4.4) se detalla esta relación.
Conviene precisar qué iguala este invariante: la pendiente máxima, no la fuerza máxima de la evidencia de un fallo. En el cociente de verosimilitudes de un fallo, el suelo de azar \(1-c_q\) se cancela y esa razón crece con la discriminación nominal \(a = a_{\text{ef}}/(1-c_q)\), no con \(a_{\text{ef}}\). Por eso un fallo en un ítem fácil de verdadero/falso (donde \(a\) llega a 2,5) aporta mucha más evidencia que el mismo fallo en una pregunta abierta: con \(\Delta\theta = 2\), la razón de verosimilitud de fallo entre niveles adyacentes es ≈ 12 en abierta, ≈ 28 en 4 opciones y ≈ 148 en verdadero/falso. Para que un solo fallo no dispare el posterior de forma casi determinista, la metodología aplica también en el caso ordinal un techo de dominio (\(P(\text{acierto}) \le 0{,}90\text{–}0{,}95\), nunca 1), el mismo que el caso nominal ya impone; además de acotar esos saltos, modela el descuido (slip) que el 3PL puro no contempla.
5.6. Entropía de Shannon
La incertidumbre del sistema se mide mediante:
Donde \(p_i\) es la probabilidad actual de cada hipótesis.
La entropía máxima, cuando todas las hipótesis son igual de probables, es:
Este valor ayuda a ajustar el umbral de parada al número de hipótesis consideradas. Véase Fundamentos §5.
5.7. Ganancia esperada de información
Para seleccionar la siguiente pregunta, el sistema puede estimar la reducción esperada de incertidumbre:
Donde \(P(A)\) es la probabilidad total esperada de acierto y \(P(F)\) la probabilidad total esperada de fallo, calculadas mediante la ley de la probabilidad total:
Las distribuciones posteriores al acierto y al fallo se calculan aplicando Bayes (§5.2) antes de obtener la respuesta real, y con ellas las entropías esperadas de cada escenario. Cuando sea posible, la pregunta más útil será la que produzca mayor reducción esperada de entropía. El desarrollo completo, con la formulación como información mutua, está en Fundamentos §6.
5.8. Verosimilitud con crédito parcial
Las fórmulas anteriores suponen que la respuesta es binaria: acierto o fallo. Pero muchas tareas se resuelven por pasos o componentes y admiten aciertos parciales. En esos casos, en lugar de clasificar la respuesta como acierto o fallo, se resume en una puntuación \(s\) entre 0 y 1. Si solo se dispone de esa puntuación agregada, la verosimilitud coherente es la geométrica: pondera la probabilidad de acierto y la de fallo con exponentes \(s\) y \(1-s\), de modo que la evidencia favorece a la hipótesis cuya probabilidad de acierto prevista se acerca más a \(s\). Con \(s=1\) equivale a un acierto pleno y con \(s=0\) a un fallo pleno; un \(s=0{,}5\) no es neutro, favorece las hipótesis intermedias. No se usa la interpolación lineal, que empujaría siempre hacia una hipótesis extrema. Cuando se conocen los componentes concretos de la respuesta, es preferible multiplicar sus verosimilitudes por separado en lugar de reducirlo todo a una sola puntuación. La fórmula, el desarrollo formal y un ejemplo numérico están en Fundamentos §4.8.
6. Verosimilitudes generadas por el sistema
Las verosimilitudes son el elemento central del sistema.
Para cada pregunta, el sistema estima:
- qué probabilidad tendría de acertarla un alumno situado en cada hipótesis;
- qué probabilidad tendría de fallarla un alumno situado en cada hipótesis.
El docente no necesita rellenar manualmente una tabla de probabilidades. Esa tarea la hace el sistema.
El docente aporta información pedagógica comprensible, como:
- número de niveles o hipótesis;
- dificultad relativa de cada pregunta;
- tipo de pregunta;
- número de opciones, si procede;
- concepto evaluado;
- posible error conceptual asociado.
Por eso, la calidad del resultado no depende solo del algoritmo, sino también de cómo esté conformada esa información de partida. Si las clasificaciones pedagógicas están mal definidas, si las dificultades no están razonablemente calibradas, si los errores conceptuales relevantes no están bien identificados o si el banco ofrece poca cobertura de los casos importantes, las verosimilitudes generadas pueden representar mal la realidad y la adaptación posterior puede salir sesgada o poco fiable.
A partir de esa información, el programa genera automáticamente las verosimilitudes. Para ello puede usar un modelo generador, preferiblemente una función logística ajustada por azar, y más adelante puede recalibrar los valores con datos reales si dispone de suficientes respuestas.
Por tanto, el flujo recomendado es:
- El docente diseña o revisa las preguntas y les asigna dificultad y formato.
- El sistema calcula automáticamente las probabilidades de acierto y fallo para cada hipótesis.
- Bayes usa esas probabilidades como verosimilitudes.
- Si se acumulan datos reales, el sistema puede ajustar sus parámetros para mejorar la calibración.
El criterio docente interviene en la definición de niveles, dificultades, objetivos y conceptos, pero no exige introducir probabilidades numéricas.
7. Verosimilitudes dinámicas por pregunta
La aplicación no depende de una tabla fija global de verosimilitudes.
Cada pregunta puede tener sus propios parámetros, especialmente:
- dificultad estimada;
- tipo de pregunta;
- número de opciones, si procede;
- probabilidad mínima de acierto por azar;
- concepto o habilidad evaluada;
- posible error conceptual asociado.
Esto permite que el sistema funcione con preguntas de distinto tipo dentro de una misma prueba.
Por ejemplo, una prueba puede incluir preguntas de dos opciones, cuatro opciones, cinco opciones, emparejamiento y respuesta numérica. Cada una genera sus propias verosimilitudes.
8. Dificultad de las preguntas
Cada pregunta tiene una dificultad estimada.
La dificultad puede expresarse de forma cualitativa, por ejemplo: fácil, media, difícil. También puede expresarse mediante una escala más flexible.
El sistema no asume que siempre habrá tres dificultades. Se adapta al número de categorías que defina el docente.
Cuando el docente define la dificultad de forma cualitativa, el sistema la convierte a valores numéricos repartiéndolos uniformemente en la mitad central de la escala de niveles: con \(k\) categorías, la más fácil y la más difícil quedan en \(\pm\theta_{\max}/2\) (con \(\theta_{\max}=n-1\), siendo \(n\) el número de niveles) y el resto a intervalos iguales. La conversión depende, por tanto, del número de niveles además del número de categorías: una tabla que dependiera solo del número de categorías sería inconsistente cuando hay pocos niveles y muchas categorías (con dos niveles, \(\theta=\pm 1\), asignaría dificultades de hasta \(\pm 2\), invirtiendo la separación entre escalas). Ejemplos: con 3 niveles y 3 categorías, \(b \in \{-1, 0, +1\}\); con 3 niveles y 5 categorías, \(b \in \{-1, -0{,}5, 0, +0{,}5, +1\}\); con 4 niveles y 3 categorías, \(b \in \{-1{,}5, 0, +1{,}5\}\). La fórmula exacta está en Fundamentos §8.3.
En consecuencia, no basta con que haya muchas preguntas: conviene que el banco esté bien distribuido en los ejes pedagógicamente relevantes del recurso, sobre todo la dificultad, el tipo de ítem y los contenidos, habilidades o errores que se quieren discriminar. Si una zona importante queda infrarrepresentada, el sistema puede parecer adaptativo y, sin embargo, razonar sobre una base pobre.
Tampoco basta con el número total. Para que la selección adaptativa no se vuelva repetitiva, hace falta redundancia local: en cada zona relevante del banco conviene disponer de varias preguntas alternativas de dificultad y función diagnóstica parecidas. Si una categoría, nivel o tipo de error solo tiene un ítem útil, el sistema tenderá a repetirlo aunque la regla de selección sea correcta.
Los valores \(\theta_i\) que representan los niveles son fijos y dependen solo del número de hipótesis (centrados en cero, con espaciado 2 y \(\theta_{\max}=n-1\)); las dificultades se sitúan dentro de esa escala, en la mitad central, y los valores atípicos se recortan a ella. Así, el rango de \(\theta\) es estrictamente mayor que el de \(b_q\) —lo que evita que las preguntas extremas confirmen débilmente los niveles extremos— y una pregunta atípica no estira la escala ni distorsiona las verosimilitudes del resto del banco. El motivo (la «regla del factor 2») y la derivación completa están en Fundamentos §8. Ese margen crece con \(n\): con \(n \geq 3\) los ítems extremos confirman con holgura, pero con \(n = 2\) (domina / no domina) la confirmación es más débil (probabilidad ≈ 0,65–0,77 según el formato), por lo que conviene compensar con más preguntas.
9. Número variable de niveles e hipótesis
El sistema admite distintos números de hipótesis:
- dos estados: domina / no domina;
- tres niveles: básico / medio / avanzado;
- cuatro niveles: inicial / básico / competente / avanzado;
- hipótesis conceptuales alternativas dentro de una misma dimensión: error A / error B / dominio correcto;
- hipótesis por necesidades, siempre que sean alternativas en la decisión que se modela: refuerzo previo / práctica guiada / consolidación / ampliación (ejemplo fronterizo: estas necesidades también pueden verse como ordinales —grados de apoyo—; trátalas como no jerárquicas solo si lo que importa es elegir entre ellas, y como ordinales si lo relevante es el orden de necesidad).
El umbral de entropía y los criterios de parada se adaptan al número de hipótesis consideradas. No conviene usar el mismo umbral para todos los diseños sin justificación.
Si se desea parar cuando la hipótesis más probable supera un nivel de confianza \(p_{\min}\) (por ejemplo, 0,80), el umbral de entropía asociado se obtiene suponiendo que la probabilidad restante se reparte uniformemente entre las otras \(n-1\) hipótesis (fórmula y derivación en Fundamentos §7). Algunos valores orientativos con \(p_{\min}=0{,}80\):
| Hipótesis \(n\) | \(H_{\text{stop}}\) (bits) |
|---|---|
| 2 | 0,72 |
| 3 | 0,92 |
| 4 | 1,04 |
| 5 | 1,12 |
La fórmula anterior supone que la probabilidad restante se reparte uniformemente entre las otras \(n-1\) hipótesis, lo que no siempre ocurre en distribuciones reales. Por ejemplo, con tres hipótesis, las distribuciones (0,80, 0,10, 0,10) y (0,80, 0,19, 0,01) tienen la misma hipótesis máxima pero distinta entropía. Por tanto, el umbral \(H_{\text{stop}}\) se entiende como una aproximación práctica, no como un equivalente exacto. Conviene saber que, cuando \(H_{\text{stop}}\) se deriva del mismo \(p_{\min}\), la condición de probabilidad máxima ya implica la de entropía (si la hipótesis más probable alcanza \(p_{\min}\), la entropía queda por debajo del umbral): comprobar las dos es inofensivo, pero no añade exigencia. El control que sí aporta algo distinto es exigir una separación mínima entre la hipótesis ganadora y la segunda, \(P(H_{\text{ganadora}}) - P(H_{\text{segunda}}) \geq \Delta_{\min}\). Ahora bien, esa separación solo añade exigencia si \(\Delta_{\min} > 2p_{\min} - 1\): con \(p_{\min} = 0{,}80\), exigir \(\max_i P(H_i) \geq p_{\min}\) ya fuerza una separación \(\geq 0{,}60\), de modo que un \(\Delta_{\min}\) de 0,3–0,4 también sería redundante. Su utilidad real es como alternativa a un \(p_{\min}\) alto: con muchas hipótesis, un máximo moderado más una separación de 0,3–0,4 es un criterio de confianza más natural que exigir \(\max_i P(H_i) \geq 0{,}80\) (véase la explicación matemática, §7.4).
Las hipótesis de una misma distribución son mutuamente excluyentes y cubren las alternativas relevantes para esa decisión. Si varios errores, lagunas o necesidades pueden coexistir, conviene usar distribuciones separadas por concepto, dimensión o categoría, en lugar de forzarlas dentro de una única lista de hipótesis.
Cuando las hipótesis no son jerárquicas —categorías alternativas sin relación de orden entre ellas, como distintas estrategias, causas alternativas de un mismo fallo o áreas temáticas sin jerarquía—, la función logística IRT puede no ser el modelo más adecuado, porque asume que existe una escala única de «más o menos nivel». En esos casos conviene definir las verosimilitudes de otra forma: por ejemplo, asignando directamente una probabilidad de acierto alta para las preguntas que diagnostican la hipótesis correcta y una probabilidad más baja para las que la confunden con otras hipótesis. La actualización bayesiana sigue siendo idéntica; solo cambia la forma de generar las verosimilitudes.
Si, en cambio, varios errores o necesidades pueden coexistir, no conviene meterlos en una sola lista de hipótesis nominales. Lo adecuado es usar una dimensión por factor o, si interesa captar sus interacciones, una distribución sobre perfiles completos (las combinaciones posibles de esos factores). En ese marco, la evidencia ideal no es solo «acierto» o «fallo», sino también qué opción ha elegido el alumno: un distractor puede ser precisamente la señal de un error concreto.
Para asignar esas probabilidades sin datos empíricos conviene un criterio explícito. Por cada pregunta y cada hipótesis, factor o perfil, estima: «si el alumno tuviera este error o esta combinación de errores, ¿con qué frecuencia acertaría esta pregunta y qué distractor elegiría?». El valor será bajo cuando la pregunta ataca justo el concepto que el error distorsiona, y alto cuando el error no interfiere. Acota cada valor entre un suelo de azar (no menos de \(1/m\), con \(m\) opciones, cuando el fallo procede de responder al azar) y un techo inferior a 1 para el dominio (en torno a 0,90–0,95, dejando margen a descuidos). Hay una única excepción justificada al suelo: si la pregunta es de opción múltiple y uno de los distractores es precisamente la respuesta que produce el error, el alumno es atraído hacia esa opción y su probabilidad de acierto cae por debajo del azar. No hace falta afinar el decimal exacto: basta con que, en las preguntas que discriminan, los perfiles correctos se separen claramente de los que el error hace fallar. La formulación matemática (§10) detalla estas variantes y su validación.
10. Tipos de preguntas admisibles
Como el sistema funciona de forma automática, usa preguntas autocorregibles.
Son adecuados, entre otros, estos formatos:
- opción múltiple con una respuesta correcta;
- verdadero/falso;
- selección múltiple con criterio claro de corrección;
- emparejamiento;
- ordenación;
- respuesta numérica con tolerancia;
- respuesta breve exacta.
No conviene incluir preguntas abiertas largas si el programa no puede corregirlas automáticamente de forma fiable.
Las preguntas abiertas pueden ser útiles en una actividad educativa general, pero no forman parte del motor adaptativo automático si no existe un mecanismo fiable de corrección o intervención docente.
11. Probabilidad de acierto por azar
En preguntas de opción múltiple, la probabilidad mínima de acierto por azar depende del número de opciones de cada pregunta. Esta probabilidad pertenece a cada ítem, no al test completo.
Ejemplos:
- pregunta de 2 opciones: probabilidad mínima de acierto por azar del 50 %;
- pregunta de 3 opciones: probabilidad mínima de acierto por azar del 33,3 %;
- pregunta de 4 opciones: probabilidad mínima de acierto por azar del 25 %;
- pregunta de 5 opciones: probabilidad mínima de acierto por azar del 20 %.
Si dentro de una misma prueba hay preguntas con distinto número de opciones, cada pregunta usa su propia probabilidad mínima de acierto por azar.
En selección múltiple con varias respuestas correctas, la probabilidad de acierto por azar puede ser distinta. El sistema trata este caso de forma específica, especialmente si se exige coincidencia exacta con la combinación correcta.
En respuestas numéricas con tolerancia o respuestas breves exactas, la probabilidad de acierto por azar puede considerarse nula o muy baja, según el diseño.
Cuando un ítem se corrige por varios componentes con distinto número de opciones —por ejemplo, una tarea con varios pasos— y se puntúa con crédito parcial, la media ponderada de los azares de cada componente representa la puntuación parcial esperada por azar, no la probabilidad de acertar el ítem completo. Ese valor puede alimentar la función logística si la curva se interpreta como puntuación esperada del ítem compuesto. Si el ítem se corrige como todo-o-nada, la probabilidad de acierto pleno por azar es el producto de los azares de los componentes independientes.
12. Uso de una función logística
Cuando proceda, las verosimilitudes pueden generarse mediante una función logística ajustada por azar.
La idea general es que la probabilidad de acierto aumenta cuando el nivel hipotético del alumno supera la dificultad de la pregunta, y disminuye cuando la dificultad supera el nivel hipotético del alumno.
Si se usa este modelo, se respetan dos condiciones importantes: la probabilidad de acierto no es inferior a la probabilidad de acierto por azar propia de la pregunta, y tampoco supera el techo de dominio (\(\le 0{,}90\)–\(0{,}95\), nunca 1) descrito en el §5.5, que modela el descuido y evita saltos casi deterministas del posterior ante un fallo.
Por tanto, una pregunta de cuatro opciones no asigna una probabilidad de acierto inferior al 25 %, porque un alumno que responde al azar tiene esa probabilidad de acertar.
La función logística no sustituye a Bayes. Solo sirve para generar las verosimilitudes que Bayes necesita.
El sistema permite que esta generación sea ajustable. Por ejemplo, puede existir un parámetro de sensibilidad o discriminación que determine cuánto separa una pregunta entre unas hipótesis y otras.
13. Selección adaptativa de la siguiente pregunta o actividad
A partir de la estimación actual, el programa selecciona dinámicamente la siguiente pregunta, explicación o actividad.
La selección busca utilidad pedagógica y puede servir para:
- confirmar una hipótesis probable;
- distinguir entre hipótesis cercanas;
- detectar un error conceptual;
- comprobar una laguna concreta;
- reforzar una dificultad;
- cubrir un contenido todavía no evaluado;
- permitir que el alumno demuestre un nivel superior;
- decidir si conviene pasar a ampliación o a refuerzo.
El sistema no se limita a subir la dificultad tras un acierto y bajarla tras un fallo.
Tiene en cuenta: historial de respuestas, conceptos ya evaluados, errores detectados, variedad de contenidos, dificultad relativa de las preguntas, tipo de pregunta, número de opciones de cada pregunta, probabilidad de acierto por azar, y grado de seguridad de la estimación actual.
Cuando varias preguntas tienen la misma ganancia de información esperada —lo que ocurre frecuentemente cuando comparten los mismos parámetros de dificultad y número de opciones—, la selección entre ellas no es determinista. Se recomienda una selección aleatoria ponderada: calcular la ganancia de todas las candidatas, reunir las que están dentro de un margen mínimo del máximo, y elegir entre ellas con una probabilidad proporcional al inverso de las veces que su categoría o concepto ha aparecido ya. Esto combina máxima utilidad informativa con diversidad temática, sin imponer restricciones rígidas. Una selección determinista entre empates produce test sistemáticamente repetitivos entre distintas sesiones.
13.1. Diagnóstico inicial y refuerzo posterior
En recursos de práctica adaptativa, refuerzo o entrenamiento por tipos, la selección no persigue siempre el mismo objetivo. Al principio conviene diagnosticar; después conviene intervenir sobre lo menos dominado.
Se recomienda una estrategia en dos fases:
- Fase diagnóstica inicial. Mientras existan categorías, conceptos o tipos de problema con menos de una muestra mínima de intentos, el sistema los prioriza. El objetivo es evitar conclusiones basadas en una muestra demasiado pequeña. Dentro de esas categorías, puede elegirse la pregunta con mayor ganancia esperada de información. Un valor por defecto razonable es exigir al menos 2 intentos por categoría. Con muchas categorías, esta fase puede consumir la sesión entera (por ejemplo, 10 categorías con 2 intentos son ya 20 preguntas): conviene agrupar categorías afines en bloques o reducir la muestra mínima para que el diagnóstico inicial no supere el máximo práctico.
- Fase de refuerzo. Cuando todas las categorías relevantes tengan muestra mínima, el sistema prioriza la categoría con menor dominio estimado o mayor necesidad pedagógica. Una vez elegida la categoría, la pregunta concreta no es necesariamente la más difícil. Conviene combinar la ganancia esperada de información con una medida de adecuación de dificultad, de modo que el sistema prefiera ejercicios informativos pero cercanos al nivel estimado del alumno.
Esta separación evita un uso excesivo de la entropía de Shannon. La entropía responde a la pregunta “¿dónde tengo más incertidumbre?”, pero no siempre responde a “¿qué necesita practicar más el alumno?”. En evaluación diagnóstica pura, maximizar la reducción de incertidumbre puede ser el criterio principal. En práctica adaptativa y refuerzo, se combina con una función de utilidad pedagógica que dé prioridad a los contenidos menos dominados.
En términos operativos, la fase de refuerzo puede usar una puntuación de utilidad como:
utilidad = α · IG_normalizada + (1 − α) · ajuste_de_dificultad
donde ajuste_de_dificultad disminuye cuando la dificultad de la pregunta se aleja mucho del nivel estimado del alumno. Un valor inicial razonable es α = 0.6 o 0.7, para conservar valor diagnóstico sin convertir el refuerzo en una sucesión de ejercicios demasiado difíciles.
Para que el peso α signifique algo, los dos sumandos deben estar en la misma escala [0, 1]: IG_normalizada = IG(q) / IG_máx entre las candidatas del momento, y ajuste_de_dificultad = máx(0, 1 − |b_q − E[θ]| / 2), que vale 1 cuando la dificultad coincide con el nivel estimado (E[θ] = Σ p_i·θ_i) y 0 cuando se aleja un intervalo completo de nivel.
13.2. Refuerzo continuo y cautela con poca evidencia
Los criterios de parada (sección 17) suponen que el objetivo es diagnosticar y cerrar. En recursos de práctica o refuerzo abierto, en cambio, puede no haber final: la sesión continúa mientras el alumno practica, y el estado estimado se entiende como una estimación viva, no como un diagnóstico cerrado. En ese modo, la entropía y la confianza sirven para informar del grado de seguridad, no para terminar la sesión, y la selección en dos fases se mantiene durante toda la práctica.
Con pocos intentos, una sola respuesta puede desplazar mucho la estimación. Para no comunicar un dominio infundado, conviene exigir una muestra mínima por categoría o dimensión antes de mostrar niveles altos de dominio, y presentar la estimación como provisional mientras la evidencia sea escasa. Es una decisión de presentación: no cambia el cálculo bayesiano, solo cómo se traduce a la interfaz.
En sesiones de práctica largas hay un matiz más: el alumno aprende mientras practica, y la actualización bayesiana pura da el mismo peso a las respuestas antiguas que a las recientes, de modo que la estimación puede quedarse anclada en un estado que el alumno ya ha superado. Para que la estimación siga su estado actual conviene aplicar un olvido gradual de la evidencia antigua (olvido exponencial): las respuestas recientes pesan más que las antiguas y el sistema recuerda, en la práctica, las últimas 10–20 respuestas. En recursos diagnósticos de sesión corta no se aplica este olvido. El mecanismo, sus valores recomendados y la extensión que modela explícitamente el aprendizaje están en la explicación matemática (§3.5).
El olvido debe atenuar la estimación hacia el prior, no hacia la uniforme: de lo contrario, cualquier prior informativo se degrada solo con el paso de la sesión. El caso más dañino es el de los factores de error: con prior \(P(\text{error}) \approx 0{,}25\), un factor que pase un tiempo sin recibir evidencia deriva hacia el 50 % y reaparece como «indeterminado» o «probable» sin que el alumno haya hecho nada, reintroduciendo el falso positivo que el prior informativo evita (§5.1). Anclado al prior, el olvido descarta la evidencia antigua pero las distribuciones sin evidencia nueva permanecen en su prior. Además, con olvido activo la muestra mínima por categoría debe contarse sobre una ventana reciente, no sobre toda la sesión: la evidencia caduca, pero un contador acumulado no. Ese contador con caducidad gobierna las puertas de dominio, no lo que se muestra al alumno: si la interfaz enseña cuántos ejercicios ha resuelto, ese número es el total real; y una categoría que se queda sin evidencia reciente ha vuelto a su prior, así que conviene presentarla como sin datos recientes y no como una debilidad.
Un matiz de calibración cuando hay varias distribuciones en paralelo: al atenuarlas todas en cada respuesta, cada una envejece una vez por respuesta pero solo recibe evidencia cuando la pregunta le corresponde. Un mismo \(\lambda\) para todas castiga a las que se actualizan con menos frecuencia: con seis categorías, el \(\lambda=0{,}95\) pensado para una memoria de veinte respuestas deja a cada categoría una memoria de poco más de tres intentos propios, suficiente para borrar el diagnóstico inicial. Por eso la memoria se fija en intentos de la propia distribución y el \(\lambda\) se deriva de ahí para cada una. La formulación exacta está en la explicación matemática (§3.5).
13.3. Itinerarios por etapas
Cuando el recurso organiza el aprendizaje en fases o etapas sucesivas —por ejemplo, un itinerario que primero trabaja una técnica y después otra—, conviene distinguir entre la estimación global del alumno y una estimación local propia de cada etapa. La creencia acumulada en etapas anteriores no debería bastar por sí sola para decidir si el alumno supera la etapa actual: esa decisión conviene tomarla con la evidencia generada dentro de la propia etapa.
Para dar una etapa por superada conviene exigir, de forma conjunta, dos tipos de condición. La primera es la confianza local: que la hipótesis local más probable supere un \(p_{\min}\) (por ejemplo, 0,80) y que la entropía local caiga por debajo del \(H_{\text{stop}}\) correspondiente. Como ya se explica en el §9 y el §17, cuando \(H_{\text{stop}}\) se deriva del mismo \(p_{\min}\), la condición de confianza ya implica la de entropía; comprobar las dos aquí es igual de inofensivo que allí, pero no añade exigencia adicional. La condición que sí aporta algo distinto es la segunda: un mínimo explícito de rendimiento observado en esa etapa. Sin ese mínimo, una estimación bayesiana muy segura —por ejemplo, si las preguntas de la etapa están mal calibradas— podría dar la etapa por superada con pocos aciertos reales; por eso conviene exigirlo aparte, no como sustituto de la confianza local sino como control adicional. Ahora bien, este rendimiento no puede medirse con el porcentaje bruto de aciertos si dentro de la etapa se seleccionan las preguntas por máxima información: en ese caso la tasa de acierto de todos los alumnos tiende por diseño hacia \((1+c)/2\) —en torno al 50-62 % según el formato—, de modo que un umbral fijo como «60 % de aciertos» puede bloquear a alumnos que dominan la etapa y su efecto depende del formato de las preguntas. Para que el criterio sea informativo conviene medirlo sobre evidencia no seleccionada por máxima información: por ejemplo, exigir el acierto de uno o dos ítems «de salida» de dificultad representativa elegidos sin criterio informativo, o comprobar que la tasa observada no queda muy por debajo de la esperada bajo la hipótesis de dominio local (el mismo ajuste de persona de Fundamentos §11.7 aplicado como criterio de etapa). Dos matices operativos: el formato de los ítems de salida importa —conviene evitar verdadero/falso, donde un solo ítem deja pasar por azar a la mayoría de quienes no dominan (\(P(\text{acierto} \mid \text{no dominio}) \approx 0{,}6\)), mientras que exigir 2 de 2 en formato abierto bloquea a ≈ 1 de cada 4 alumnos que sí dominan; el filtro complementa la confianza local, no decide en solitario—. Y con los pocos ítems de una etapa la aproximación normal del ajuste de persona es débil: conviene comparar aciertos observados frente a esperados con un margen de ~1 desviación típica (o un test binomial exacto) y tratarlo como señal orientativa, no como bloqueo duro. Todo esto lo aplica el propio recurso de forma automática, a partir de las dificultades que ya conoce: no requiere que el docente conozca la metodología ni configure nada, salvo que quiera hacerlo.
Si el alumno repite una etapa, conviene reiniciar la estimación local de esa etapa en lugar de arrastrar el estado anterior, salvo que exista una justificación pedagógica explícita para lo contrario. Terminar una etapa tampoco implica necesariamente haberla superado: el sistema puede proponer recorrerla de nuevo o reforzarla antes de avanzar.
El ejemplo itinerario para despejar la x, citado en el §3.1, aplica este patrón: mantiene una estimación local por etapa además de la global, y decide la promoción de etapa con la evidencia generada dentro de ella.
14. Reducción esperada de incertidumbre
Cuando es posible, el sistema selecciona la pregunta que más reduce la incertidumbre esperada.
Para ello estima, antes de presentar la pregunta:
- qué ocurriría si el alumno acierta;
- qué ocurriría si el alumno falla;
- cómo cambiaría la distribución de probabilidades en cada caso;
- qué entropía tendría cada distribución posterior;
- cuál sería la incertidumbre esperada después de formular esa pregunta.
Si el estado se representa con varias distribuciones paralelas (factores de error o dimensiones diagnósticas), la ganancia se calcula primero por distribución y después se agrupa en bloques pedagógicos —por ejemplo, nivel global, errores, categorías o etapas—. Dentro de un bloque puede sumarse la ganancia de sus distribuciones, porque en la representación factorizada la entropía conjunta es la suma de entropías. Para combinar bloques, conviene normalizar la ganancia de cada bloque entre las candidatas disponibles y aplicar pesos automáticos inferidos de la finalidad. Valores por defecto: si la finalidad se centra en un bloque, peso 0,7 para ese bloque y 0,3 repartido entre los demás; si es mixta, pesos iguales por bloque, no por número bruto de dimensiones. Un bloque se considera decidido cuando alcanza su criterio de confianza (el de nivel, al superar \(p_{\min}\) con el mínimo de preguntas; el de errores, cuando todos sus factores salen de la zona indeterminada con su muestra mínima); su peso se reparte entonces proporcionalmente entre los bloques aún inciertos. Estos pesos no se piden al docente; los decide la IA desde la intención educativa expresada. Dos cautelas: la utilidad combinada no está en bits —la normalización reescala el mejor candidato de cada bloque a 1 aunque sus ganancias sean minúsculas—, así que el criterio de parada por ganancia mínima debe evaluarse sobre la ganancia cruda total, nunca sobre la utilidad normalizada; y un bloque casi agotado puede quedar sobrerrepresentado justo antes de quedar decidido: si eso resulta visible, se ponderan las ganancias crudas (media por dimensión) o se normaliza por la entropía restante del bloque.
La mejor pregunta no tiene por qué ser la que coincide con el nivel más probable. Puede ser una pregunta que ayude a distinguir entre dos hipótesis todavía plausibles.
Por ejemplo, si el sistema duda entre nivel medio y avanzado, una pregunta difícil puede ser más útil que una pregunta media. Si duda entre básico y medio, una pregunta media o fácil puede ser más informativa, según las verosimilitudes.
Maximizar la reducción de incertidumbre tiene un efecto secundario que conviene conocer: las preguntas más informativas tienden a ser aquellas cuya probabilidad de acierto ronda el 50 %, de modo que el alumno fallará aproximadamente la mitad de lo que responda durante el diagnóstico. Es lo óptimo desde el punto de vista informativo, pero puede tener coste motivacional con alumnado joven o con dificultades. Una decisión pedagógica razonable —y opcional— es abrir con una pregunta asequible o intercalar alguna de éxito probable, aceptando una pequeña pérdida de eficiencia a cambio de sostener la confianza del alumno.
15. Mecanismos de recuperación
Cuando la selección de preguntas se realiza por máxima ganancia de información esperada, la recuperación queda en gran parte integrada en el propio mecanismo bayesiano: si el alumno inicialmente falla pero después responde correctamente preguntas más difíciles, el posterior se desplaza automáticamente y el sistema selecciona preguntas más exigentes. No suele ser necesaria una lógica de recuperación explícita, pero la recuperación completa no está garantizada si las preguntas están mal calibradas, si hay pocas disponibles en algún nivel, o si el alumno responde al azar.
Los mecanismos de recuperación explícitos solo son necesarios cuando la selección de preguntas se basa en reglas simples de dificultad (subir tras acierto, bajar tras fallo), porque en ese caso el sistema puede quedar bloqueado en un nivel incorrecto. Si se usa selección por ganancia de información, el riesgo de bloqueo se reduce mucho, porque el sistema reevalúa el posterior tras cada respuesta. Aun así, puede haber bloqueos prácticos si el banco de preguntas es limitado, si las verosimilitudes están mal calibradas o si se detiene la prueba demasiado pronto.
Pistas dentro de un ítem. Ofrecer una pista antes de que el alumno responda cambia la probabilidad de acierto de ese ítem: un acierto tras una pista no es la misma evidencia de dominio que un acierto sin ayuda. Para no sobrestimar el nivel, ese acierto no debe registrarse como acierto pleno, sino como crédito parcial con una puntuación \(s < 1\), tanto menor cuanto más determinante haya sido la pista (si la pista prácticamente da la respuesta, la evidencia de dominio es casi nula). Así se reutiliza la verosimilitud geométrica del crédito parcial (Fundamentos §4.8) en lugar de tratar el acierto asistido como si fuera espontáneo.
Reutilización de ítems tras la corrección. El mismo razonamiento se aplica a un ítem que se repite después de que el alumno haya visto su corrección o explicación (incluido el reintento inmediato): el acierto posterior puede reflejar solo memoria del feedback, no dominio. Ese acierto no debe registrarse como evidencia plena: se trata como crédito parcial con \(s\) reducido —tanto menor cuanto más explícita fue la explicación mostrada— o, si la explicación dio la respuesta, se excluye de la actualización y cuenta solo como práctica. La mejor redundancia local no es repetir el mismo ítem, sino disponer de variantes parametrizadas del mismo tipo (mismo concepto, dificultad y formato con datos distintos): cada variante cuenta como ítem nuevo y no arrastra la contaminación del feedback.
Lo que sí se garantiza en cualquier diseño:
- El sistema no encierra al alumno de forma irreversible en una categoría inicial.
- Si el alumno falla al principio pero después muestra señales consistentes de dominio, el posterior bayesiano se encargará de reflejar ese cambio.
- Si el alumno empieza con aciertos pero después muestra errores relevantes, el sistema revisará la distribución de probabilidades.
- La adaptación es dinámica en cada respuesta, no solo al inicio o al final.
16. Entropía de Shannon como medida de incertidumbre
La seguridad razonable se estima mediante la entropía de Shannon aplicada a la distribución de probabilidades de las hipótesis.
Cuando las probabilidades están muy repartidas, la entropía es alta y el sistema tiene mucha incertidumbre. Cuando una hipótesis concentra la mayor parte de la probabilidad, la entropía es baja y el sistema tiene más seguridad.
La entropía sirve para:
- decidir si conviene seguir preguntando;
- comparar la incertidumbre antes y después de una pregunta;
- seleccionar preguntas informativas;
- determinar si el diagnóstico final es firme o provisional.
El umbral de parada se ajusta al número de hipótesis consideradas y al grado de precisión deseado.
17. Criterios de finalización
El proceso termina cuando hay una seguridad razonable sobre el estado de aprendizaje del alumno o cuando se alcanza un límite práctico.
Los criterios posibles son:
- La entropía cae por debajo del umbral \(H_{\text{stop}}\) y la hipótesis más probable supera \(p_{\min}\). Cuando \(H_{\text{stop}}\) se deriva del mismo \(p_{\min}\), la segunda condición ya implica la primera; comprobar las dos es inofensivo. El control que sí aporta algo distinto es exigir una separación mínima respecto a la segunda hipótesis (\(P(H_{\text{ganadora}}) - P(H_{\text{segunda}}) \geq \Delta_{\min}\)), útil sobre todo como alternativa a un \(p_{\min}\) alto: solo añade exigencia si \(\Delta_{\min} > 2p_{\min} - 1\) (véase §9).
- Se alcanza un número máximo de preguntas. Conviene distinguir entre un máximo teórico y un máximo práctico. El primero puede estimarse mediante búsqueda minimax sobre el árbol de respuestas posibles; el segundo se fija por usabilidad. En una demo o herramienta educativa breve puede imponerse, por ejemplo, un tope duro de 20 preguntas, mostrando resultado provisional si no se ha convergido antes.
- La mejor pregunta disponible deja de ser útil. Si, tras un número suficiente de preguntas, la ganancia esperada de información de la mejor candidata cae por debajo de un umbral mínimo, conviene detener la sesión y devolver un diagnóstico provisional en lugar de alargarla artificialmente.
- Ya se han cubierto los conceptos mínimos previstos.
- No quedan preguntas útiles disponibles.
- El coste de seguir preguntando supera la ganancia pedagógica esperada.
En modelos multifactoriales la parada se evalúa por factor: un factor queda decidido cuando su probabilidad marginal sale de la zona indeterminada (por ejemplo, presente si \(P(\text{error}) \geq 0{,}7\), ausente si \(\leq 0{,}3\)) y cuenta con su muestra mínima de evidencia. Se cierra cuando todos los factores están decididos, cuando ningún ítem aporta ganancia apreciable sobre los indeterminados o al alcanzar el máximo práctico; los factores sin decidir se reportan como indeterminados, no se fuerzan.
Si la entropía final sigue siendo alta, el sistema lo indica claramente. En ese caso, el resultado se presenta como una estimación provisional, no como una conclusión firme.
18. Resultado final
El resultado final se presenta como una interpretación pedagógica.
El resultado incluye, cuando proceda:
- qué parece dominar el alumno;
- qué dificultades muestra;
- qué errores conceptuales son probables;
- qué lagunas conviene revisar;
- qué tipo de refuerzo se recomienda;
- qué actividad de avance podría proponerse;
- qué grado de seguridad tiene la estimación;
- si el diagnóstico es firme o provisional.
No se limita a mostrar una puntuación o una etiqueta.
Cuando dos hipótesis terminan con probabilidades próximas, conviene mostrar la distribución posterior completa (por ejemplo, mediante un diagrama de barras) en lugar de una sola etiqueta ganadora.
En el diagnóstico por factores de error con prior informativo (\(P(\text{error}) \approx 0{,}2\)–\(0{,}3\)), la ausencia arranca ya en 0,7–0,8 sin evidencia alguna: un factor no debe declararse ausente solo porque su marginal supere el umbral de confianza. El resultado debe exigir además la muestra mínima de evidencia de ese factor y distinguir «ausente confirmado» (con evidencia) de «sin evidencia suficiente» (el valor por defecto del prior).
Si el recurso combina una estimación ordinal de nivel con factores de error, ambas son estimaciones marginales paralelas alimentadas por la misma evidencia, no hallazgos independientes: el resultado final debe presentarse de forma coherente. Si el nivel estimado es alto y algún error queda «presente», se presenta como matiz del nivel («domina X, aunque persiste el error Y»), no como conclusiones contradictorias yuxtapuestas.
La finalidad del sistema es ayudar a tomar decisiones educativas.
19. Adaptación al contexto docente
El concepto de recurso educativo adaptativo se entiende de forma amplia. Un test adaptativo es solo un caso particular. La misma lógica puede aplicarse a explicaciones, prácticas, simuladores, itinerarios, sistemas de pistas, actividades de refuerzo, ampliación o recomendación de recursos. Lo importante es que el recurso tome decisiones pedagógicas a partir de las evidencias que obtiene durante la interacción con el alumno.
La implementación concreta se adapta al contexto educativo que indique el docente.
Antes de diseñar el sistema, conviene recoger información sobre:
- tema o unidad didáctica;
- edad o curso del alumnado;
- objetivos de aprendizaje;
- número de niveles o hipótesis;
- tipos de preguntas o interacciones permitidas;
- número aproximado de preguntas o pasos;
- duración máxima;
- tipo de recurso adaptativo deseado (evaluación, práctica, itinerario, tutorial, simulador, juego, recomendador, repaso…);
- finalidad principal (detectar nivel, identificar errores, reforzar, practicar, consolidar, ampliar, guiar, recomendar…);
- qué aspecto adapta el sistema (dificultad, tipo de actividad, explicación, ayuda, pistas, ritmo, itinerario…);
- tipo de salida esperada (diagnóstico, informe de progreso, ruta de aprendizaje, propuesta de siguiente actividad…);
- formato deseado;
- grado de precisión necesario.
El sistema adapta sus decisiones a ese contexto.
20. Reglas de diseño para la IA
En síntesis, una implementación fiel a este protocolo cumple estas reglas:
- No crea un recorrido rígido ni un test lineal.
- No se limita a subir dificultad tras acierto y bajarla tras fallo.
- Representa el estado del alumno mediante probabilidades sobre hipótesis.
- Actualiza esas probabilidades de forma gradual.
- Genera dinámicamente las verosimilitudes, sin exigir al docente que introduzca tablas de probabilidades.
- Tiene en cuenta la dificultad de cada pregunta.
- Tiene en cuenta el número de opciones de cada pregunta.
- No usa preguntas abiertas largas si no se pueden corregir automáticamente.
- Selecciona preguntas por utilidad pedagógica e información esperada.
- Usa entropía de Shannon para medir incertidumbre.
- Permite recuperación ante estimaciones iniciales equivocadas.
- Presenta el resultado como interpretación pedagógica.
- Indica cuándo la estimación es provisional.
- Se adapta al contexto proporcionado por el docente.
- Evita detalles técnicos innecesarios si el usuario solo necesita metodología.
21. Alcance y límites
Este protocolo no sustituye al criterio docente.
El sistema puede ayudar a orientar decisiones, pero conviene interpretar sus resultados con prudencia, especialmente cuando:
- hay pocas preguntas;
- las preguntas no están bien calibradas;
- las verosimilitudes iniciales proceden de un modelo generador no calibrado con datos reales;
- el alumno responde al azar;
- el contexto de aplicación es muy limitado;
- la entropía final sigue siendo alta.
El valor principal del enfoque está en hacer explícita la incertidumbre y en adaptar la actividad a las evidencias disponibles.
Cuando el resultado vaya a usarse para decisiones, debe acompañarse de comprobaciones de fiabilidad que no requieren datos empíricos: un índice de ajuste del patrón de cada alumno (detecta respuestas incoherentes con la dificultad, que harían el diagnóstico poco fiable aunque la confianza sea alta) y una validación del diseño por simulación (estima, antes de aplicar el test, en qué medida el banco separa los niveles). Ambas se describen en los fundamentos matemáticos (§11.7–§11.8) y miden fiabilidad bajo el modelo, no validez empírica. Si la IA genera el recurso en un entorno con ejecución, debe correr esa simulación; si trabaja en un chat sin ejecución, debe dejar preparada una utilidad de validación para la vista docente/autora y marcar el resultado como «validación pendiente de ejecutar», sin afirmar que el banco ya está comprobado.
Esa validación bajo el modelo no sustituye la revisión del contenido, que es lo único que el docente puede validar mejor que el sistema y no requiere conocer la metodología. Al entregar el recurso, la IA debe generar una lista de comprobación breve en lenguaje docente: si los errores modelados son errores reales de su alumnado, si alguna pregunta es demasiado fácil o difícil para el curso, si las respuestas correctas y las explicaciones son correctas, si falta algún caso importante del tema y si el lenguaje es adecuado a la edad. Si el docente señala un problema con sus palabras, la IA ajusta el banco o el modelo; no se le pide que revise parámetros ni probabilidades.
En recursos de aprendizaje prolongados —tutoriales, práctica adaptativa, refuerzo o ampliación—, el estado del alumno puede cambiar durante la propia sesión. En esos casos, el posterior no se interpreta solo como diagnóstico de un estado fijo, sino como una estimación dinámica que puede combinar evidencias recientes, ayudas utilizadas, progreso observado y cambios en el desempeño. El mecanismo de olvido exponencial descrito en los fundamentos matemáticos (§3.5) concreta esta idea haciendo que las respuestas recientes pesen más que las antiguas.
22. Referencias
El desarrollo matemático del modelo (inferencia bayesiana, entropía de Shannon, teoría de respuesta al ítem) y su bibliografía completa están en la explicación matemática detallada.
Como fundamento pedagógico específico de este protocolo:
- Black, P. & Wiliam, D. (1998). Assessment and Classroom Learning. Assessment in Education: Principles, Policy & Practice, 5(1), 7–74. [Evaluación formativa.]
- Bloom, B. S. (1968). Learning for Mastery. Evaluation Comment, 1(2). UCLA. [Aprendizaje para el dominio; base de los mecanismos de refuerzo y recuperación.]
Cómo citar este documento (APA 7): de Haro, J. J. (2026). Protocolo para sistemas educativos adaptativos bayesianos (versión 2.0). https://jjdeharo.github.io/recursos-adaptativos/documentacion.html
El desarrollo formal de los mecanismos descritos en este protocolo —inferencia bayesiana, modelo IRT, entropía de Shannon y selección adaptativa— se encuentra en el documento complementario Fundamentos matemáticos, que incluye fórmulas, demostraciones y un ejemplo numérico completo.